数据库笔记5-数据库基本原理
数据的存储方式
聚簇(clustering)
为提高某个属性(组)的查询速度,将这些属性上具有相同值的元组存在连续的物理块中称为聚簇。该属性(组)称为
聚簇码(cluster key)
聚簇的优点
- 在数据库系统中,I/O操作的时间开销很大,而聚簇大大降低了I/O操作
- 聚簇也适用于多个常用于连接的关系,即把多个连接关系的元组按连接属性值聚簇存放,相当于
预连接。 - 一个数据库可以有多个聚簇,一个关系只能加入一个聚簇。
聚簇的缺点
- 聚簇建立维护开销很大,需要与优点权衡
- 对已有关系建立聚簇,会移动数据的物理地址,即原索引全部失效,需要重新建立索引
- 聚簇码值修改会导致数据物理地址移动
聚簇的选择要求
- 经常进行连接操作的关系
- 关系中的一组属性经常出现在相等比较中
- 关系的个或一组属性上的值重复率很高。即聚簇码值平均元组数不能太少。
- SQL语句经常出现
ORDER BY、GROUP BY、UNION、DISTINCT等子句。 - 不经常进行全表扫描
- 连接操作多于更新操作
- 一个表只能加入一个聚簇,如果有一个表符合多个,则选择最优的
索引
索引法(B+树、Hash)
B+树索引法
一般条件:
- 一个(组)属性经常在查询条件中出现,考虑在该属性上建立(组合)索引
- 一个属性经常作为最大值和最小值等聚集函数的参数,考虑建立索引
- 一个(组)属性经常在连接操作的连接条件中出现,考虑建立索引
注意:
若一个关系更新频率很高,则要花费大量时间更新索引,因此不适合建立太多索引
Hash索引法
一般条件:
- 一个关系的大小可预知,且不变。
- 关系的大小动态改变,但数据库管理系统提供了动态hash存储方法。
查询的执行方式
数据库查询四个步骤:查询分析、查询检查、查询优化、查询执行
- 查询分析
对查询语句进行扫描、词法、语法分析,没有错误则进行下一步。 - 查询检查
对合法的查询语句进行语义检查,根据数据字典检查各对象是否存在和有效和权限检查,如果是视图操作,则需转换成对基本表的操作。 - 查询优化
选择一个高效的查询策略,一般分为代数优化、物理优化。代数优化是修改代数表达式的操作和组合实现优化;物理优化是指存储路径和底层操作算法,物理优化可以基于规则、代价、语义。 - 查询执行
根据优化器得到的查询策略,通过代码生成器生成查询计划并进行查询。
选择操作实现
- 选择操作只涉及一张表,一般用简单全表扫描或索引扫描。
- 若选择率低,索引扫描效率更高。
- 若选择率高,全表扫描效率高,因为B+树索引的扫描操作,对于每个检索码,从根结点到叶子结点,每个结点都要执行一次I/O操作。
1)简单全表扫描法
设可用内存M
- 按照物理次序读M的数据到内存
- 检查内存每个元组t,满足则输出
- 若表没读完,则重复1-2操作
2)索引扫描法
- 若选择条件的数学有索引(B+树、Hash),则可以通过索引先找到满足条件的元组指针,再通过指针在基本表中找到元组。
- 若干选择条件包含多个带索引的属性,有以下两种方法:
- 各属性分别利用索引找到满足条件的指针组,最后将各组指针取交集。
- 选某个属性利用索引找到满足条件的指针组,遍历这个指针组对应的元组,检查是否满足其他属性的条件,满足则输出。
连接操作实现
连接操作是查询处理最常用也最耗时的操作之一。常用等值连接算法思想:
1) 嵌套循环算法
- 最简单可行通用的算法,可以处理等值与非等值的连接
- 以一张表为外循环,另一张表作为内循环,根据连接条件判断是否连接
- 实际实现时是按照数据库读入内存,而不是按照元组I/O
2) 排序-合并算法
- 将参与连接的表根据连接条件进行排序
- 取出一张表的第一个连接属性,并扫描找到另一张表连接属性相同值,然后开始连接。(因为排了序,后面都是连续可连接的)
- 开始连接后,当遇到第一个不可连接的元组时,第一个对象连接结束。
- 重复上述过程,直到连接结束。
特点:
- 两个表都只遍历了一遍
- 一般来说,对于大表,先排序再连接,效率也比嵌套循环好
3) 索引连接算法
设SC表上已有Sno索引
- 对每一个Student元组,根据Student.Sno值,利用SC的Sno索引,快速找到SC.Sno
- 将Student元组和SC元组连接起来
4) hash join算法
- 划分阶段:也称创建阶段,连接属性作为hash码,将较小的表散列到hash表中。
- 试探阶段:也称连接阶段,将另一张表用同一个hash函数进行散列,并将来自大表的元组和hash表中来自小表的元组相匹配的元组连接起来。
- 前提:较小的表可完全放入内存中,不满足前提则需要其他优化后的算法
查询优化
查询优化概述
集中式数据库中,查询执行开销主要包括:磁盘存取块数(I/O代价)、处理机时间(CPU代价)、查询的内存开销。
在分布式数据库中还要加上通信代价。
即总代价=I/O代价+CPU代价+内存代价+通信代价
其中,I/O代价比内存操作相比要高几个数量级,因此计算代价时一般用查询处理读写的块数作为衡量单位。
查询优化的优点
- 用户无需考虑最好的表达查询以获得较高的查询
- 系统优化可以比用户程序的优化做的更好,因为:
- 优化器可以从数据字典中获取许多统计信息。
- 若物理统计信息变了,优化器可以重新优化,即无需重写程序。
- 优化器可以考虑到数百种查询计划,而程序员一般只能考虑到有限的几种。
- 优化器使用了很多复杂的优化技术,而这些技术不是所有人都能掌握的,即使用了优化器,相当于普通程序员也能使用到这些技术。
举个栗子
select student.sname from student,sc where student.sno = sc.sno and sc.cno='2'
以上SQL语句可以等价于以下三种关系代数表达式:
Q1=πSname(σStudent.Sno=SC.Cno='2'(Student × SC))Q2=πSname(σSC.Cno='2'(Student ⋈ SC))Q3=πSname(Student ⋈ (σSC.Cno='2'(SC)))
假设学生记录1000个,选课记录10000个,2号课选修记录50个
情况1
1) 连接:
- 先将Student表尽可能存在内存中,留出一块放SC表的元组,然后将SC中的元组与Student的元组连接,连接后的元组写入中间文件中
- 再从SC中读入一块和内存中的Student元组连接,直到SC表处理完。
- 这时再一次读入剩下的Student元组,也留一块放SC表元组,重复操作,直到Student处理完。
简单理解:Studen只读一遍,分多批读,每一批Student要遍历所有SC。
设一个块能装10个Student元组或100个SC元组,在内存中放五块Student元组和1块SC元组,则读取总数为:1000/10 + 1000/(10*5) * 10000/100 = 100+20*100=2100块
其中读Student100块,读SC表20遍,每遍100块,则总计要读2100块。
连接后的元组数:1000*10000=1e7,设一个块存10个元组,则写出1e6个块。
2) 选择:
假设内存操作时间忽略不计,读取第一步的中间文件1e6块,满足条件的50个元组均可放在内存。
3) 投影:
将第二部的结果在Sname上投影,得到结果。
总读写数据块:2100 + 1e6 + 1e6
情况2
- 自然连接读取策略不变,与情况1一致为2100块,但连接结果只有1e4个元组,写出数据库1e3
- 读取数据块1e3做选择操作
- 投影输出,最终读写数据块
2100 + 1e3 + 1e3
代价为情况1的 1/488
情况3
- 先遍历一次SC,读取100块,将满足条件的50个元组筛选出来,不用使用中间文件
- 读取Student表一遍,100块,并与SC连接。
- 将结果投影输出
- 总代价为
100+100
第三种情况是第一种的万分之一,是第二种的20分之一
情况4
若SC在Cno上有索引,StudentSno上有索引,SC找到符合条件的50个元组,只需通过读取索引块(大约3-4块),再通过Student上的sno索引,也能更快速找到50个满足条件的student元组,并连接输出结果。
代数优化
关系代数表达式等价变化规则
- 连接、笛卡尔积的交换律
- 连接、笛卡尔积的结合律
(E1 × E2) × E3 = E1 × (E2 × E3)
(E1 ⋈ E2) ⋈ E3 = E1 ⋈ (E2 ⋈ E3) - 投影的串接定律
在投影的基础上再一次投影等价于一次性全部投影 - 选择的串接定律
- 选择与投影的交换律
- 选择与笛卡尔积的交换律
- 选择与并的分配律
- 选择与差的分配律
- 选择与自然连接的分配律
- 投影与笛卡尔积的分配律
- 投影与并的分配律
查询树的启发式优化:
- 选择运算优先做(对比情况2和情况3)
- 投影运算和选择运算同时进行,对同一个表的操作避免重复扫描。
- 把投影前或后的双目运算结合起来,没有必要为了去掉某些字段而扫描一遍表。(例如情况3,没有必要先将Student的Sno和Sname投影出来后再与SC连接)
- 把某些选择同它之前要执行的笛卡尔积结合成一个连接运算(对比情况1和情况2)
- 找出公共表达式,若读取公共查询结果代价小于重新计算代价可以,避免重复计算
查询树优化示例:
select Student.Sname from Student,SC where Student.Sno = SC.Sno and SC.Cno = '2';
查询树图
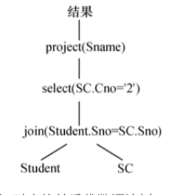
关系代数语法树
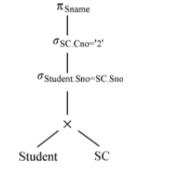
优化后的查询树
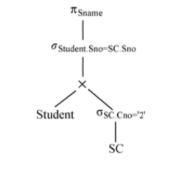
物理优化
物理优化方法一般有:
- 基于规则的启发式优化
- 基于代价估算的优化
- 两者结合的算法
基于启发式规则的存储路径选择优化
选择操作的启发式规则
- 对于小表,使用全表顺序扫描,即使选择列上有索引
- 对于大表,启发式规则:
- 选择条件为
主码=值,其选择结果唯一,可选择主码索引。 - 选择条件为
非主属性=值,选择列上有索引,估算目标元组比例小于10%,可以使用索引扫描,否则全表扫描。 - 选择条件为非等值查询,选择列上有索引,估算目标元组比例小于10%,可以使用索引扫描,否则全表扫描。
- 对于多属性
AND选择条件,若多属性上有组合索引优先使用组合索引,如果只有部分属性有索引,则考虑:- 用不同索引取出相应的指针组,并取交集(所有属性都有各自的索引)
- 用一个索引取出一个指针组,然后遍历其他属性(遍历时有索引用索引)
- 对于
OR选择条件,一般使用全表顺序扫描。
连接操作的启发式规则
- 如果2个表都已经按照连接属性排序,则选用
排序-合并算法 - 如果一个表在连接属性上有索引,则选择
索引连接算法 - 1-2方法不使用,可以考虑选较小的表选用
hash join算法 - 如果1-3不适用,则考虑
嵌套循环算法,并选择占用块较小的表作为外循环。
基于代价估算的优化
- 基于启发式的算法是定性的,比较粗糙,实现简单代价较小,适合解释执行的系统。
- 若在编译执行的系统,由于可以一次编译,多次执行,因此可以考虑加入一些精细复杂的基于代价的优化。
可考虑的统计信息:
- 对于基本表,元组总数
N、元组长度l、占用块数B、占用的溢出块数BO - 对于基本表的列,该列不同值的个数
m、该列最大值、最小值、是否有索引、何种索引(B+树、Hash、聚簇),根据这些数据可以算出谓词条件的选择率f,如果值分布均匀则f=1/m,否则需要算出每个值的选择率。 - 对于索引,如B+树索引,该索引的层数
L、不同索引值的个数、索引的选择基数S(有S个元组具有某个索引值)、索引的叶节点数Y
代价估算示例
全表扫描算法估算
基本表大小B块,全表扫描代价B,等值扫描,平均代价为B/2索引连接算法估算
等值条件,代价L+1,L为索引层数,1为目标所在那一块嵌套循环算法估算
代价为Br+BrBs(K-1)
如果要把结果写回磁盘则为Br+BrBs(K-1)+(Frs*Nr*Ns)/Mrs
Br、Bs分别为R表和S表占用的块数B
K为内存缓存区块数(其中K-1块给外表)
Frs为连接选择率
Mrs是存放连接结果的块因子,表示每块中可以存放结果元组数
具体算法参考前文的栗子
- 排序-合并算法估算
如果已经排好序代价为Br+Bs+(Frs*Nr*Ns)/Mrs
如果未排序则需要加上2*B+(2*B*log2B)
基于语义的物理优化
上述主要描述了基于规则和基于代价的物理优化方法,基于语义的方式仅举个栗子:select * from Student where Student.age >= 200
数据库系统发现,查询条件中年龄最大值小于200,因此无需读取基本表,直接返回空值。
版权声明:本博客所有文章除特殊声明外,均采用 CC BY-NC 4.0 许可协议。转载请注明出处 Marig_Weizhi的博客!